Xorshiftは2003年に発表された疑似乱数列生成法で、HD6301/6303が使われていた時代にはまだ無かったアルゴリズムです。
今回はXorshiftをHD6301/6303に実装してみようと思います。
16ビットのXorshift
Xorshiftは本来32ビット以上で実装するので8ビットCPUには少し荷が重いです。
昔の雑誌に載っているプログラムを調べてみると、ほとんどは100以下の乱数で済んでいるのでもっと少ないビット数で良しとします。
ネットで検索していると下記ページに16ビットXorshiftのアルゴリズムが載っていました。
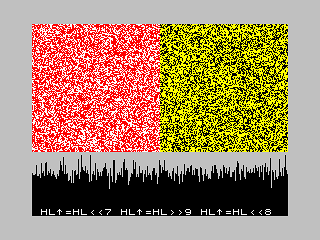
/* 16-bit xorshift PRNG */
unsigned xs = 1;
unsigned xorshift()
{
xs ^= xs << 7;
xs ^= xs >> 9;
xs ^= xs << 8;
return xs;
}シフト回数はいくつかのパターンがありますが、8ビットに近い方がコードを組みやすそうなので(7,9,8)を選びました。周期は216-1です。
まずはPythonで実装してみます
正しく実装できているかどうか「正解」が欲しいので、まずはPythonで確認することにしました。
xs = 1
for i in range(10):
xs ^= (xs << 7) & 0xffff
xs ^= (xs >> 9) & 0xffff
xs ^= (xs << 8) & 0xffff
print(hex(xs)[2:6])
# result
# 8181
# 6021
# e999
# 2e0b
# b59e
# d9a3
# 2f27
# 45f9
# 9c25
# 6ce2乱数シードは1、生成を10回繰り返しました。この数値を「解答」とします。
HD6301/6303で実装
シフトしてXORするだけなので簡単です。とはいえHD6301/6303は1ビットずつのシフトしかできませんので、少し工夫しています。
Xorshift部分のみ下記に示します。
RndNumber .bs 2 ; 乱数
xorshift_16:
ldd <RndNumber
; xs ^= xs << 7
; abcd efgh ijkl mnop ==> hijk lmno p000 0000
lsrd ; 0abc defg hijk lmno -> p
tba ; hijk lmno hijk lmno -> p
rorb ; hijk lmno phij klmn -> o
andb #$80 ; hijk lmno p000 0000 -> o
eora <RndNumber
eorb <RndNumber+1
std <RndNumber
; xs ^= xs >> 9
; abcd efgh ijkl mnop ==> 0000 0000 0abc defg
tab ; abcd efgh abcd efgh
clra ; 0000 0000 abcd efgh
lsrd ; 0000 0000 0abc defg -> h
eora <RndNumber
eorb <RndNumber+1
std <RndNumber
; xs ^= xs << 8
; abcd efgh ijkl mnop ==> ijkl mnop 0000 0000
tba ; ijkl mnop ijkl mnop
clrb ; ijkl mnop 0000 0000
eora <RndNumber
eorb <RndNumber+1
std <RndNumber
rtsこのように、8ビットシフトは上位または下位バイトがゼロになることを利用しています。
シードを1にして10回生成した画面です。サービスルーチンのwrite_wordを使用しています。
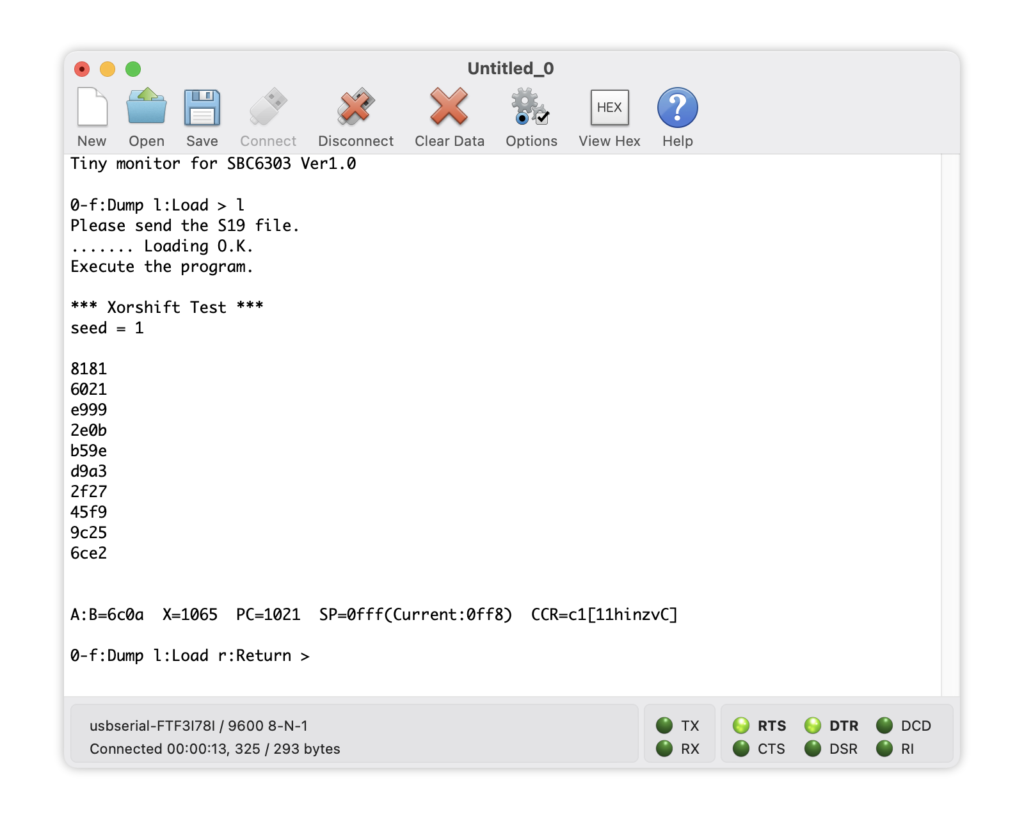
同じ数値がでました!
最適化してみます
よく見ると18行目と26行目はゼロとXORで変化しないので不要です。
ということは16行目と24行目のゼロクリアも不要になります。
さらには20行目と27行目もDレジスタではなく、A,Bレジスタでよくなります。
これを踏まえたコードがこちらです。
xorshift_16_b:
ldd <RndNumber
; xs ^= xs << 7
lsrd
tba
rorb
andb #$80
eora <RndNumber
eorb <RndNumber+1
std <RndNumber
; xs ^= xs >> 9 の上位8bitはゼロとのXORなので変化しない。
tab
lsrb
eorb <RndNumber+1
stab <RndNumber+1
; xs ^= xs << 8 の下位8bitはゼロとのXORなので変化しない。
tba
eora <RndNumber
staa <RndNumber
rts
実行してみます。
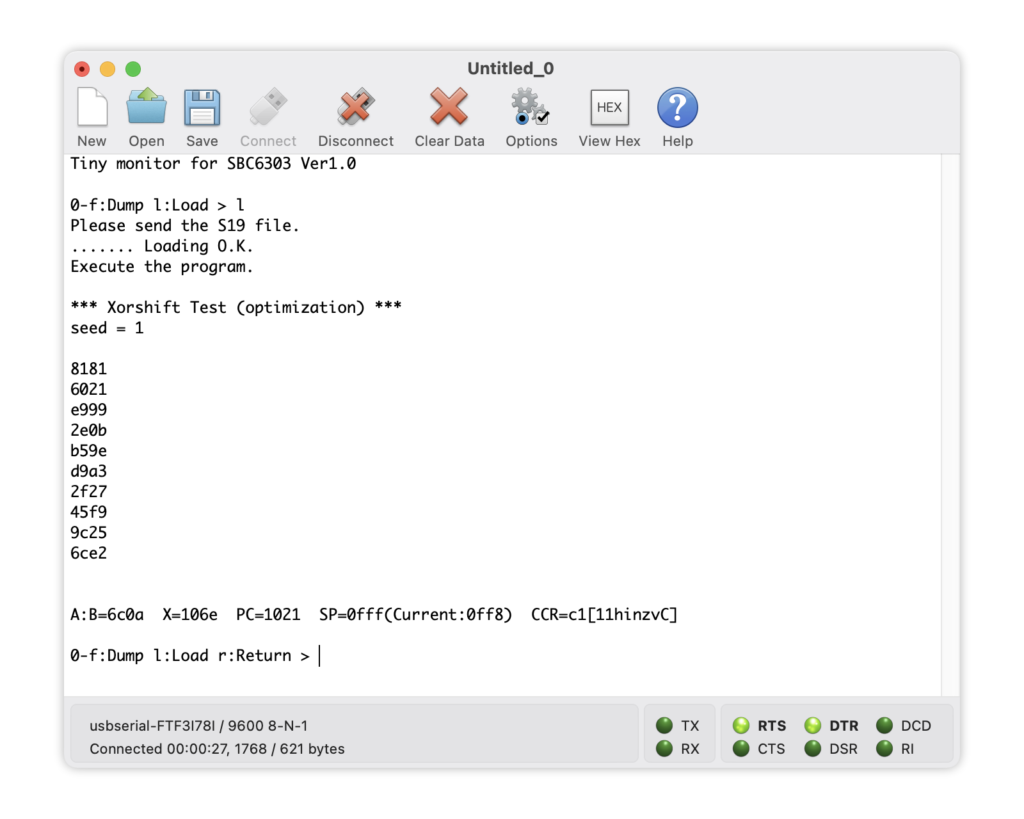
同じ数値がでました!
さらに良い方法を考えた方がいました
私にはここまでが限界だったのですが、さらに短いコードで実装している方がいました。

MOS6502用なのですが、HD6301/6303に移植してみました。
xorshift_16_c:
ldab <RndNumber
lsrb
ldab <RndNumber+1
rorb
eorb <RndNumber
stab <RndNumber ; high part of x ^= x << 7 done
rorb ; B has now x >> 9 and high bit comes from low byte
eorb <RndNumber+1
stab <RndNumber+1 ; x ^= x >> 9 and the low part of x ^= x << 7 done
tba
eora <RndNumber
staa <RndNumber ; x ^= x << 8 done
rtsなんだか良く分からないコードですが、うまくいくんでしょうか?
16ビットのデータabcdefghijklmnopがどのように変化するか調べました。
まずは元々のアルゴリズムです。
xs = a,b,c,d | e,f,g,h | i,j,k,l | m,n,o,p
xs = <<7 h,i,j,k | l,m,n,o | p,0,0,0 | 0,0,0,0
xs ^= xs a^h,b^i,c^j,d^k | e^l,f^m,g^n,h^o | i^p,j,k,l | m,n,o,p
xs >> 9 0,0,0,0 | 0,0,0,0 | 0,a^h,b^i,c^j | d^k,e^l,f^m,g^n
xs ^= xs a^h,b^i,c^j,d^k | e^l,f^m,g^n,h^o |
i^p,a^h^j,b^i^k,c^j^l | d^k^m,e^l^n,f^m^o,g^n^p
xs << 8 i^p,a^h^j,b^i^k,c^j^l | d^k^m,e^l^n,f^m^o,g^n^p | 0,0,0,0 | 0,0,0,0
xs ^= xs i^p^a^h,a^h^j^b^i,b^i^k^c^j,c^j^l^d^k |
d^k^m^e^l,e^l^n^f^m,f^m^o^g^n,g^n^p^h^o |
i^p,a^h^j,b^i^k,c^j^l | d^k^m,e^l^n,f^m^o,g^n^p次にVeikko Sariola氏のコードです。
ldab high ; a,b,c,d | e,f,g,h
lsrb ; 0,a,b,c | d,e,f,g -> h
ldab low ; i,j,k,l | m,n,o,p
rorb ; h,i,j,k | l,m,n,o -> p
eorb high ; a^h,b^i,c^j,d^k | e^l,f^m,g^n,h^o
stab high
rorb ; p,a^h,b^i,c^j | d^k,e^l,f^m,g^n -> h^o
eorb low ; p^i,a^h^j,b^i^k,c^j^l | d^k^m,e^l^n,f^m^o,g^n^p
stab low
tba
eora high ; p^i^a^h,a^h^j^b^i,b^i^k^c^j,c^j^l^d^k |
d^k^m^e^l,e^l^n^f^m,f^m^o^g^n,g^n^p^h^oおお!確かに同じ結果になっています。
XOR 0では変化しないことと、キャリーフラグをうまく使って上位8ビットと下位8ビットの計算を別々に、かつ順番を変更することでより短いコードで実現している…んだと思います。すごい!
実行してみます。
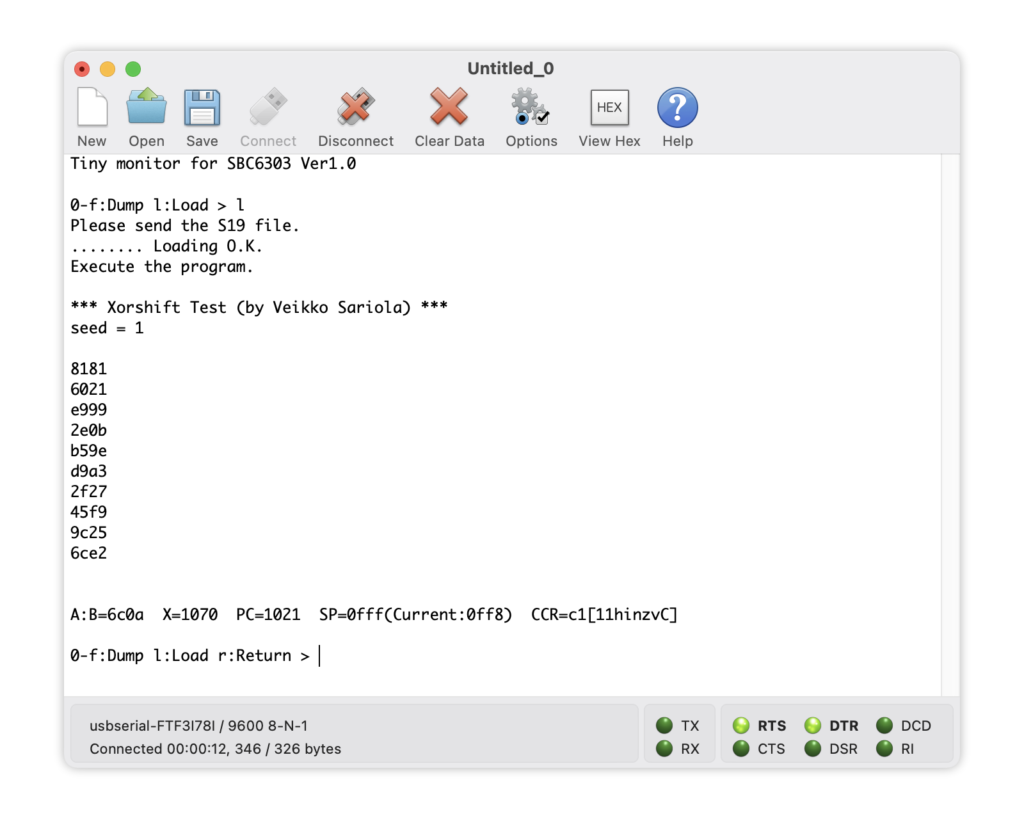
同じ数値がでました!
シード値は?
乱数生成ではシード値をどうするかも問題です。
幸いHD6301/6303にはフリーランニングカウンターがありますので、乱数生成が必要になるタイミングでFRC($09)を読み出し、シード値にしようと思います。
Xorshiftではシード値が1違うだけでかなり異なる数値が生成されるので都合がいいです。
ただし、Xorshiftのシード値はゼロ以外でないといけません。


コメント